The document storage of OGo projects is implemented as a server based plugin
API. This contains some more information on that.
related to some recent discussion ... TODO: write much more ;-)
A "project"?
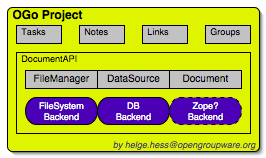 An OGo "project" is a groupware object that acts a central collection of other OGo objects and has associated tasks, contacts, notes, .. - and an associated document storage.
An OGo "project" is a groupware object that acts a central collection of other OGo objects and has associated tasks, contacts, notes, .. - and an associated document storage.
The document storage itself is implemented by plugins (bundles) which
fill the "DocumentAPI" with functionality.
Document storage
The document storage itself is attached to the project by using a "url" which in turn instantiates a document storage plugin based on the URL scheme (eg file:// activates the file backend, skydb:// the DB backend).
Right now we have two kinds of OGo specific backends:
a) a database based backend which stores metadata and hierarchy in the database and BLOBs in the filesystem and
b) a filesystem based backend which maps 1:1 to a Unix filesystem.
So a) has features, like fast queries over all document meta data (eg, also in a flat way like in a Notes database), simple co/ci versioning, ACLs. Of course using a RDBMS for filesystems also has a drawback on performance for "regular" access.
And b) is, as said a 1:1 mapping to the Unix FS. So it doesn't support versioning, ACLs etc, but is very fast.
The DocumentAPI Triangle
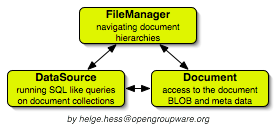 The DocumentAPI uses three abstractions which are implemented by the
backend plugins - Document, DataSource and FileManager. A document
corresponds to a file and contains the "raw" content of the document (also
called BLOB) and the metadata associated with the file. A filemanager
allows hierarchical navigation in the document tree, that is, it can list the
contents of a directory for some path. It mirrors the usual
Unix API, eg it also allows to retrieve the BLOB of a file as an data object.
And finally, the datasource is probably the most powerful of the three, it
allows to run SQL like queries on a set of documents - usually either all
documents of a project or the documents of a certain subfolders.
The DocumentAPI uses three abstractions which are implemented by the
backend plugins - Document, DataSource and FileManager. A document
corresponds to a file and contains the "raw" content of the document (also
called BLOB) and the metadata associated with the file. A filemanager
allows hierarchical navigation in the document tree, that is, it can list the
contents of a directory for some path. It mirrors the usual
Unix API, eg it also allows to retrieve the BLOB of a file as an data object.
And finally, the datasource is probably the most powerful of the three, it
allows to run SQL like queries on a set of documents - usually either all
documents of a project or the documents of a certain subfolders.
And what about attaching Zope?
So for Zope I would invent a new backend plugin which accesses the Zope database using either WebDAV and/or XML-RPC. Indeed it probably makes sense to write a generic WebDAV backend and extend that with Zope specific operations in a subclass.
On the other side it might be faster for us to use only XML-RPC in the beginning, since we have a stable client here. I'm really interested how Zope accessed via XML-RPC or WebDAV performs against the DB backend in practice (whether the XML overhead is higher or the DB transaction overhead).
And Subversion?
We also have a prototypical document storage based on Subversion. We'll
see, maybe one day, when Subversion becomes stable, we'll use that as the
default storage.
Update: well, Subversion is stable now with
1.0 released and 1.1 being in the queue. So
we should seriously consider adding a Svn
backend.
Note: compatibility of the APR and Subversion
Apache licenses with GPL and LGPL needs to
be investigated.
And my Xyz System?
Well, let us know about your
system ;-)
